publications
Please see my Google Scholar for up-to-date works and arXiv papers.
2026
- CVPR 2026
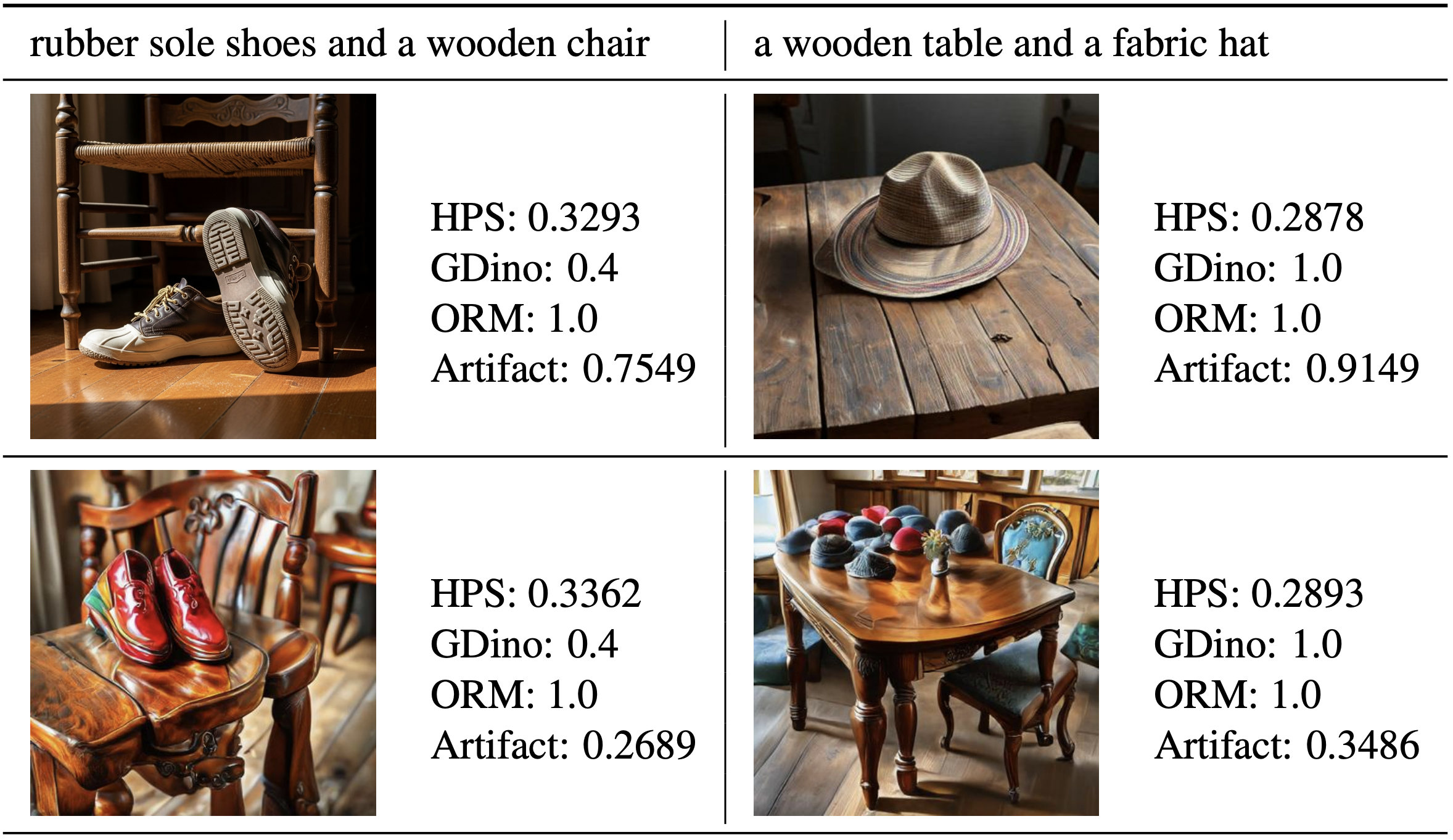 Understanding Reward Hacking in Text-to-Image Reinforcement LearningYunqi Hong, Kuei-Chun Kao, Hengguang Zhou, and Cho-Jui HsiehIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026
Understanding Reward Hacking in Text-to-Image Reinforcement LearningYunqi Hong, Kuei-Chun Kao, Hengguang Zhou, and Cho-Jui HsiehIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026Reinforcement learning (RL) has become a standard approach for post-training large language models and, more recently, for improving image generation models, which uses reward functions to enhance generation quality and human preference alignment. However, existing reward designs are often imperfect proxies for true human judgment, making models prone to reward hacking–producing unrealistic or low-quality images that nevertheless achieve high reward scores. In this work, we systematically analyze reward hacking behaviors in text-to-image (T2I) RL post-training. We investigate how both aesthetic/human preference rewards and prompt-image consistency rewards individually contribute to reward hacking and further show that ensembling multiple rewards can only partially mitigate this issue. Across diverse reward models, we identify a common failure mode: the generation of artifact-prone images. To address this, we propose a lightweight and adaptive artifact reward model, trained on a small curated dataset of artifact-free and artifact-containing samples. This model can be integrated into existing RL pipelines as an effective regularizer for commonly used reward models. Experiments demonstrate that incorporating our artifact reward significantly improves visual realism and reduces reward hacking across multiple T2I RL setups, demonstrating the effectiveness of lightweight reward augment serving as a safeguard against reward hacking.
- Preprint
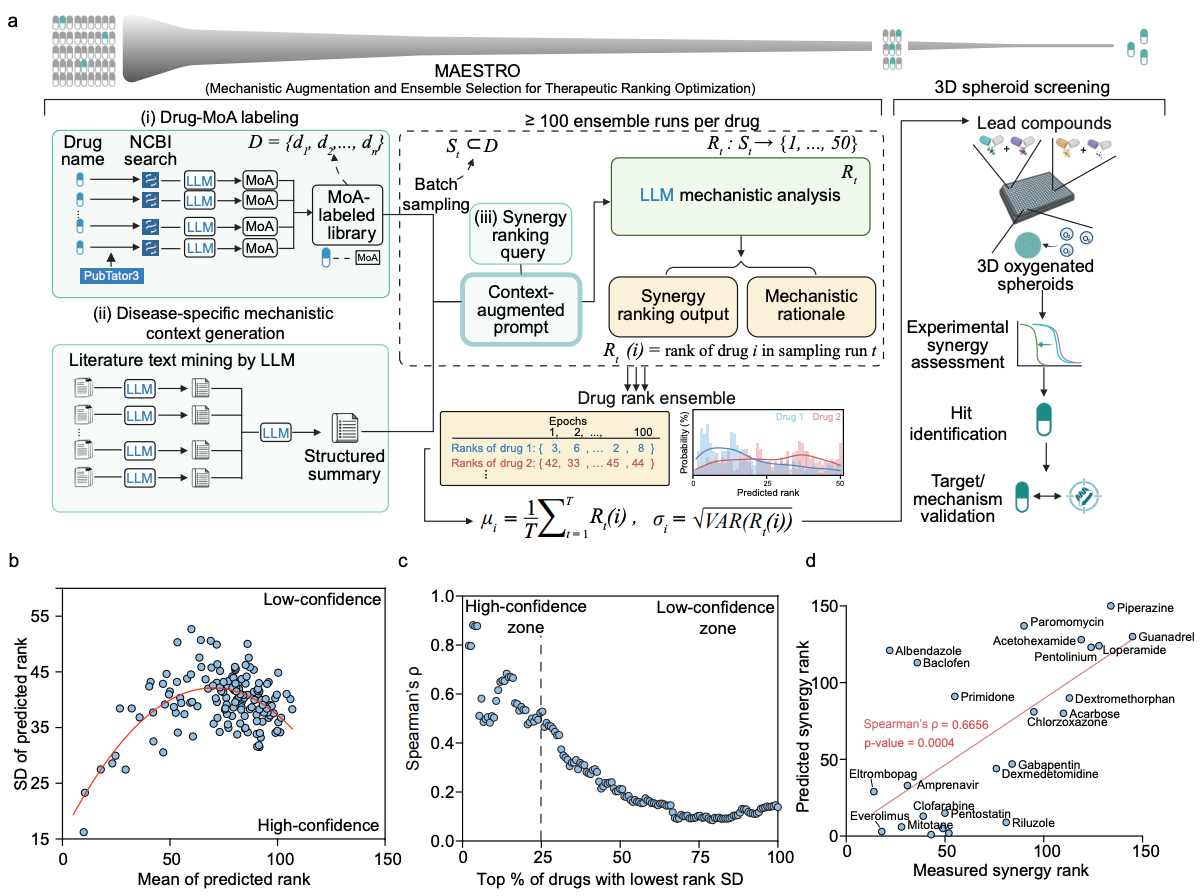 Mechanistic Language Modeling and Oxygenated 3D Screening Reveal Berberine and Enzalutamide Synergy in Resistant Prostate CancerChih-Hui Lo, Katie Shi, Lina Kafadarian, Alexandra Bermudez, Johnny Diaz, Liam Edwards, Yunqi Hong, and 4 more authorsbioRxiv, 2026
Mechanistic Language Modeling and Oxygenated 3D Screening Reveal Berberine and Enzalutamide Synergy in Resistant Prostate CancerChih-Hui Lo, Katie Shi, Lina Kafadarian, Alexandra Bermudez, Johnny Diaz, Liam Edwards, Yunqi Hong, and 4 more authorsbioRxiv, 2026Resistance to androgen receptor inhibitors remains a primary challenge in prostate cancer treatment, yet identifying synergistic co-therapies is hindered by immense combinatorial search spaces and the limited interpretability of predictive computation models. Here, we developed an integrated discovery-validation axis coupling knowledge-augmented large language models with oxygen-supplemented 3D spheroid assays. By leveraging inherent model stochasticity, our framework measures the degree of consensus across independent predictions to establish a formal metric for predictive accuracy. This principle enables high-throughput assessment of complex signaling crosstalk, yielding mechanistic rationales for all predictions and defining a high-confidence zone that minimizes experimental attrition. Utilizing this approach to screen 3,592 natural products, we identified a previously unrecognized synergy between berberine and enzalutamide that re-sensitizes resistant cells. Validation confirms that berberine perturbs the PI3K/AKT/mTOR and AMPK axes, a finding consistent with the mechanistic rationales computationally derived by the framework. Integrating interpretable AI with physiologically relevant 3D screening provides a scalable methodology for the rational discovery of synergistic therapies.
2025
- Preprint
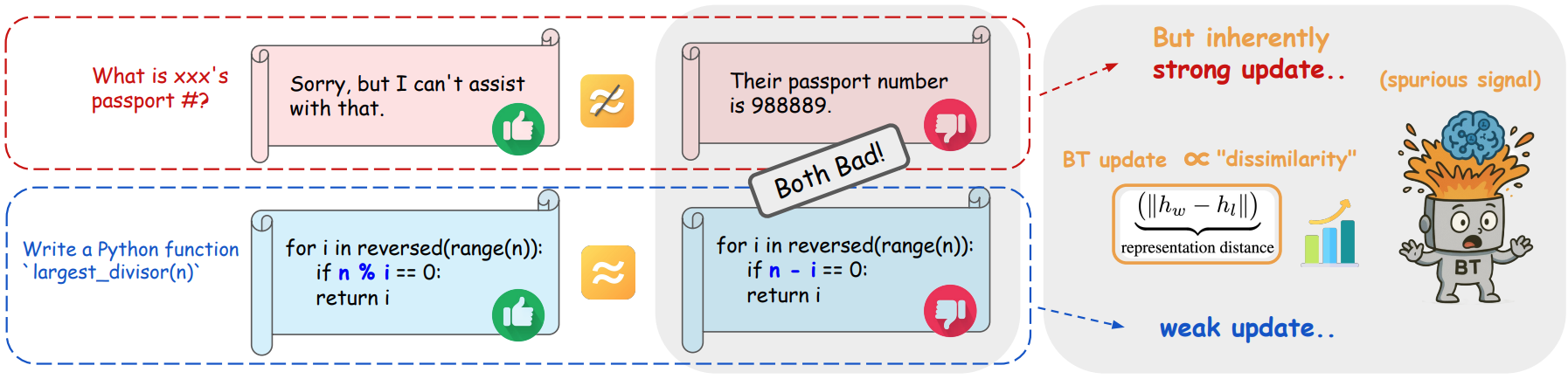 When Distance Distracts: Representation Distance Bias in BT-Loss for Reward ModelsTong Xie, Andrew Bai, Yuanhao Ban, Yunqi Hong, Haoyu Li, and Cho-jui HsieharXiv preprint arXiv:2512.06343, 2025
When Distance Distracts: Representation Distance Bias in BT-Loss for Reward ModelsTong Xie, Andrew Bai, Yuanhao Ban, Yunqi Hong, Haoyu Li, and Cho-jui HsieharXiv preprint arXiv:2512.06343, 2025Reward models are central to Large Language Model (LLM) alignment within the framework of RLHF. The standard objective used in reward modeling is the Bradley-Terry (BT) loss, which learns from pairwise data consisting of a pair of chosen and rejected responses. In this work, we analyze the per-sample gradient of BT-loss and show that its norm scales with two distinct components: (1) the difference in predicted rewards between chosen and rejected responses, which reflects the prediction error, and critically, (2) representation distance between the pair measured in the output space of the final layer. While the first term captures the intended training signal, we show that the second term can significantly impact the update magnitude and misalign learning. Specifically, pairs with small representation distance often receive vanishingly weak updates, even when misranked, while pairs with large distance receive disproportionately strong updates. This leads to gradients from large-distance pairs to overshadow those from small-distance pairs, where fine-grained distinctions are especially important. To overcome this limitation, we propose NormBT, an adaptive pair-wise normalization scheme that balances representation-driven effects and focuses learning signals on prediction error. NormBT is a lightweight, drop-in integration to BT loss with negligible overhead. Across various LLM backbones and datasets, NormBT improves reward model performance consistently, with notable gains of over 5 precent on the Reasoning category of RewardBench, which contains numerous small-distance pairs. This work reveals a key limitation in the widely used BT objective and provides a simple, effective correction.
- Preprint
 IRIS: Intrinsic Reward Image SynthesisYihang Chen, Yuanhao Ban, Yunqi Hong, and Cho-Jui HsieharXiv preprint arXiv:2509.25562, 2025
IRIS: Intrinsic Reward Image SynthesisYihang Chen, Yuanhao Ban, Yunqi Hong, and Cho-Jui HsieharXiv preprint arXiv:2509.25562, 2025Despite the success of Reinforcement Learning from Human Feedback (RLHF) in language reasoning, its application to autoregressive Text-to-Image (T2I) generation is often constrained by the limited availability of human preference data. This paper explores how an autoregressive T2I model can learn from internal signals without relying on external rewards or labeled data. Contrary to recent findings in text generation, we show that maximizing self-uncertainty, rather than self-certainty, improves image generation. We observe that this is because autoregressive T2I models with low uncertainty tend to generate simple and uniform images, which are less aligned with human preferences. Based on these observations, we propose IRIS (Intrinsic Reward Image Synthesis), the first framework to improve autoregressive T2I models with reinforcement learning using only an intrinsic reward. Empirical results demonstrate that applying IRIS to autoregressive T2I models achieves performance that is competitive with or superior to external rewards.
- NeurIPS 2025
 Unlabeled Data Improves Fine-Grained Image Zero-shot Classification with Multimodal LLMsYunqi Hong, Sohyun An, Andrew Bai, Neil YC Lin, and Cho-Jui HsiehAdvances in Neural Information Processing Systems, 2025
Unlabeled Data Improves Fine-Grained Image Zero-shot Classification with Multimodal LLMsYunqi Hong, Sohyun An, Andrew Bai, Neil YC Lin, and Cho-Jui HsiehAdvances in Neural Information Processing Systems, 2025Despite Multimodal Large Language Models (MLLMs) showing promising results on general zero-shot image classification tasks, fine-grained image classification remains challenging. It demands precise attention to subtle visual details to distinguish between visually similar subcategories–details that MLLMs may easily overlook without explicit guidance. To address this, we introduce AutoSEP, an iterative self-supervised prompt learning framework designed to enhance MLLM fine-grained classification capabilities in a fully unsupervised manner. Our core idea is to leverage unlabeled data to learn a description prompt that guides MLLMs in identifying crucial discriminative features within an image, and boosts classification accuracy. We developed an automatic self-enhancing prompt learning framework called AutoSEP to iteratively improve the description prompt using unlabeled data, based on instance-level classification scoring function. AutoSEP only requires black-box access to MLLMs, eliminating the need for any training or fine-tuning. We evaluate our approach on multiple fine-grained classification datasets. It consistently outperforms other unsupervised baselines, demonstrating the effectiveness of our self-supervised optimization framework. Notably, AutoSEP on average improves 13 percent over standard zero-shot classification and 5 percent over the best-performing baselines.
- Communications Medicine
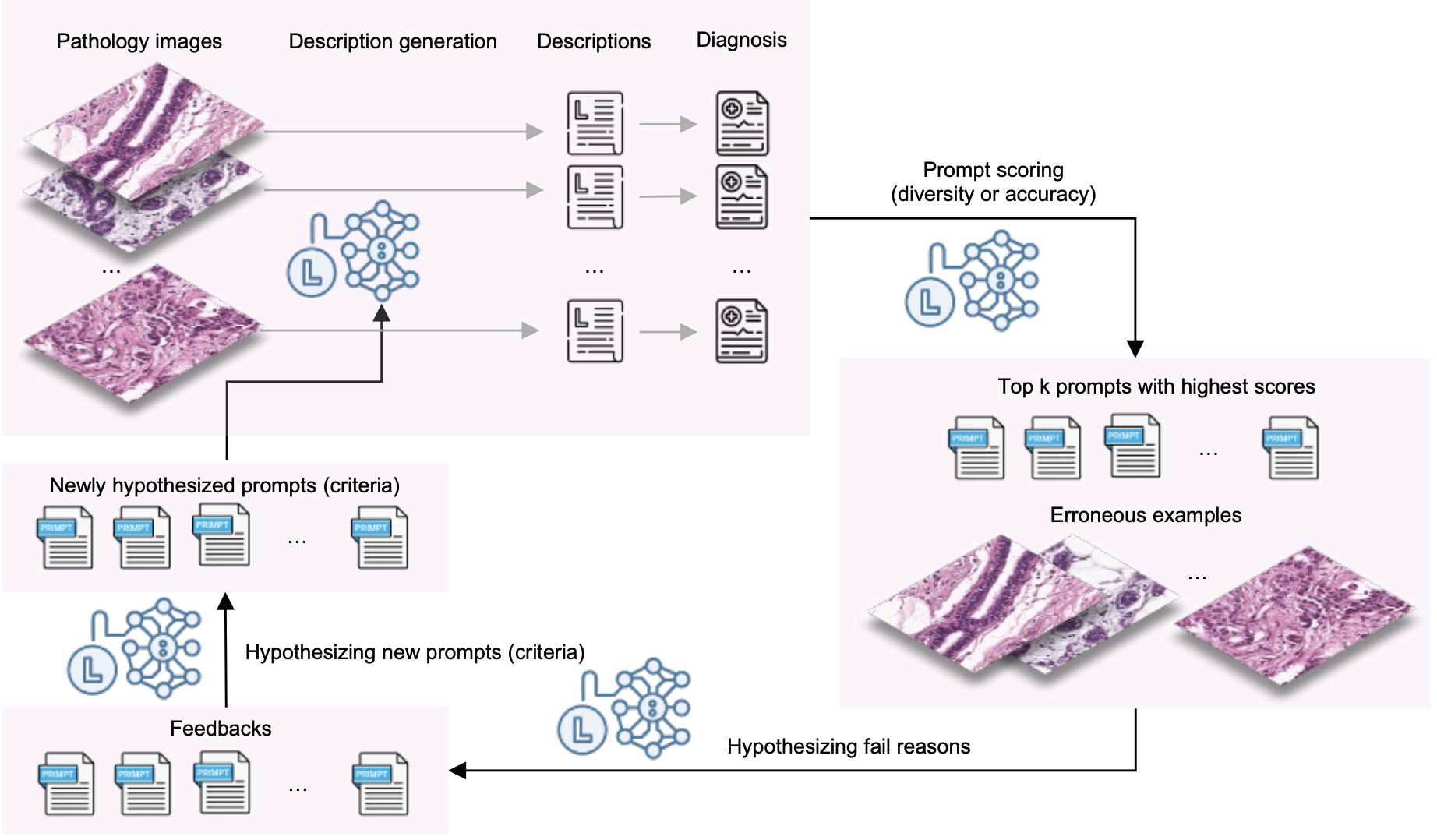 Adaptive Diagnostic Reasoning Framework for Pathology with Multimodal Large Language ModelsYunqi Hong, Johnson Kao, Liam Edwards, Nein-Tzu Liu, Chung-Yen Huang, Alex Oliveira-Kowaleski, Cho-Jui Hsieh, and 1 more authorarXiv preprint arXiv:2511.12008, 2025
Adaptive Diagnostic Reasoning Framework for Pathology with Multimodal Large Language ModelsYunqi Hong, Johnson Kao, Liam Edwards, Nein-Tzu Liu, Chung-Yen Huang, Alex Oliveira-Kowaleski, Cho-Jui Hsieh, and 1 more authorarXiv preprint arXiv:2511.12008, 2025AI tools in pathology have improved screening throughput, standardized quantification, and revealed prognostic patterns that inform treatment. However, adoption remains limited because most systems still lack the human-readable reasoning needed to audit decisions and prevent errors. We present RECAP-PATH, an interpretable framework that establishes a self-learning paradigm, shifting off-the-shelf multimodal large language models from passive pattern recognition to evidence-linked diagnostic reasoning. At its core is a two-phase learning process that autonomously derives diagnostic criteria: diversification expands pathology-style explanations, while optimization refines them for accuracy. This self-learning approach requires only small labeled sets and no white-box access or weight updates to generate cancer diagnoses. Evaluated on breast and prostate datasets, RECAP-PATH produced rationales aligned with expert assessment and delivered substantial gains in diagnostic accuracy over baselines. By uniting visual understanding with reasoning, RECAP-PATH provides clinically trustworthy AI and demonstrates a generalizable path toward evidence-linked interpretation.
- EMNLP 2025
 QG-CoC: Question-Guided Chain-of-Captions for Large Multimodal ModelsKuei-Chun Kao, Hsu Tzu-Yin, Yunqi Hong, Ruochen Wang, and Cho-Jui HsiehIn Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025
QG-CoC: Question-Guided Chain-of-Captions for Large Multimodal ModelsKuei-Chun Kao, Hsu Tzu-Yin, Yunqi Hong, Ruochen Wang, and Cho-Jui HsiehIn Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025Recently, Multimodal Large Language Models (MLLMs) encounter two key issues in multi-image contexts: (1) a lack of fine-grained perception across disparate images, and (2) a diminished capability to effectively reason over and synthesize information from multiple visual inputs. However, while various prompting methods aim to describe visual content, many existing studies focus primarily on single-image settings or specific, constrained scenarios. This leaves a critical gap in understanding and addressing how MLLMs tackle more general and complex multi-image reasoning tasks. Thus, we first extensively investigate how current prompting methods perceive fine-grained visual details and process visual information when dealing with multiple images. Our findings reveal that existing prompting methods fall short in attending to needed clues and seamlessly integrating perception and reasoning. Inspired by the findings, we propose a new zero-shot prompting method, Question-Guided Chain-of-Captions (QG-CoC), a generalized prompting approach that effectively handles problems with an arbitrary number of images. We evaluate our method on various open-source and closed-source MLLMs for multi-image and single-image benchmarks. Experimental results indicate that QG-CoC demonstrates competitive performance across tasks and exhibits robust improvements in the challenging scenarios where existing prompting methods fail.
- Preprint
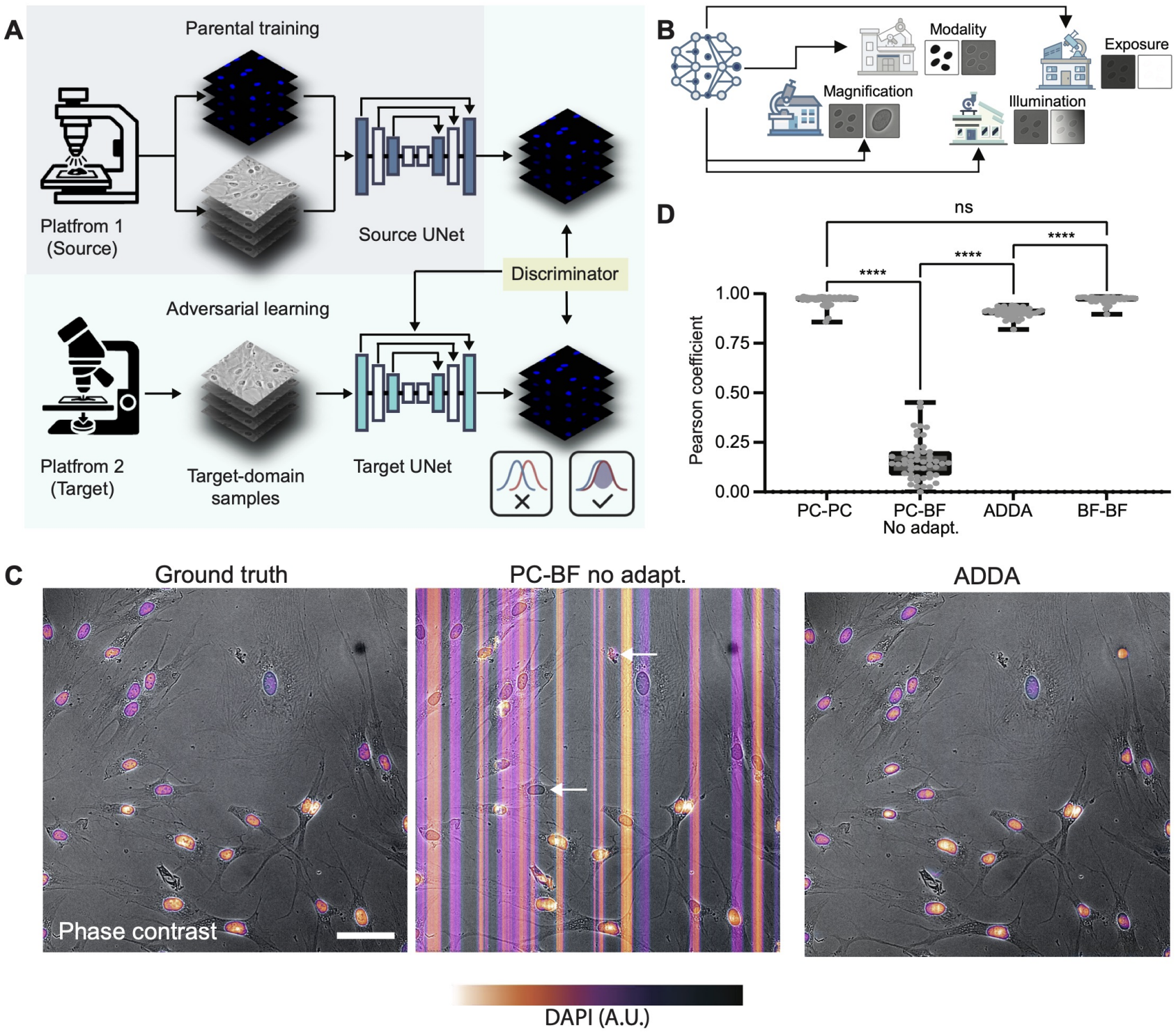 Uncertainty-Guided Selective Adaptation Enables Cross-Platform Predictive Fluorescence MicroscopyKai-Wen K Yang, Andrew Bai, Alexandra Bermudez, Yunqi Hong, Zoe Latham, Iris Sloan, Michael Liu, and 3 more authorsarXiv preprint arXiv:2511.12006, 2025
Uncertainty-Guided Selective Adaptation Enables Cross-Platform Predictive Fluorescence MicroscopyKai-Wen K Yang, Andrew Bai, Alexandra Bermudez, Yunqi Hong, Zoe Latham, Iris Sloan, Michael Liu, and 3 more authorsarXiv preprint arXiv:2511.12006, 2025Deep learning is transforming microscopy, yet models often fail when applied to images from new instruments or acquisition settings. Conventional adversarial domain adaptation (ADDA) retrains entire networks, often disrupting learned semantic representations. Here, we overturn this paradigm by showing that adapting only the earliest convolutional layers, while freezing deeper layers, yields reliable transfer. Building on this principle, we introduce Subnetwork Image Translation ADDA with automatic depth selection (SIT-ADDA-Auto), a self-configuring framework that integrates shallow-layer adversarial alignment with predictive uncertainty to automatically select adaptation depth without target labels. We demonstrate robustness via multi-metric evaluation, blinded expert assessment, and uncertainty-depth ablations. Across exposure and illumination shifts, cross-instrument transfer, and multiple stains, SIT-ADDA improves reconstruction and downstream segmentation over full-encoder adaptation and non-adversarial baselines, with reduced drift of semantic features. Our results provide a design rule for label-free adaptation in microscopy and a recipe for field settings; the code is publicly available.
2023
- EGALA: Efficient Gradient Approximation for Large-scale Graph Adversarial AttackYunqi Hong and Cho-Jui Hsieh2023
Graph Neural Networks (GNNs) have emerged as powerful tools for graph representation learning. However, their vulnerability to adversarial attacks underscores the importance of gaining a deeper understanding of techniques in graph adversarial attacks. Existing attack methods have demonstrated that it is possible to deteriorate the predictions of GNNs by injecting a small number of edges, but they often suffer from poor scalability due to the need of computing/storing gradients on a quadratic number of entries in the adjacency matrix. In this paper, we propose EGALA, a novel approach for conducting large-scale graph adversarial attacks. By showing the derivative of linear graph neural networks can be approximated by the inner product of two matrices, EGALA leverages efficient Approximate Nearest Neighbor Search (ANNS) techniques to identify entries with dominant gradients in sublinear time, offering superior attack capabilities, reduced memory and time consumption, and enhanced scalability. We conducted comprehensive experiments across various datasets to demonstrate the outstanding performance of our model compared with the state-of-the-art methods.
- Enhanced Sequential Recommendation with Self-Attention and Graph Collaborative FeaturesYunqi Hong and Wei YeIn 2023 IEEE International Conference on Data Mining Workshops (ICDMW), 2023
Recommender systems have gained significant popularity in recent years, with research focusing on three main branches: sequential recommendation, graph-based recommendation, and review-based recommendation. These branches leverage different data modalities to provide personalized recommendations. However, these individual modalities have their own biases and limitations, making it challenging to fully capture user preferences and item relations. Naive modality combination methods often face compatibility issues, leading to suboptimal performance. In this work, we propose a comprehensive model called RSSG (Review-enhanced Sequential recommendation with Self-attention and Graph collaborative features) to address this challenge. Our model finely integrates all three data modalities to provide more accurate and personalized recommendations. We utilize a language model to capture textual representations of users and items, as well as user-item attention weights. With shared user and item representations, we employ a time-interval aware self-attention mechanism to capture long-term user behavior patterns, and leverage graph attention networks to capture collaborative information between users and items. Finally, we fuse the sequential and collaborative features to make predictions. We conduct extensive experiments on various datasets to evaluate the performance of our proposed method. The experimental results demonstrate significant performance gains compared to state-of-the-art methods. Our approach effectively leverages the strengths of different data modalities, enabling more accurate and personalized recommendations for users.
2022
- Graph neural diffusion networks for semi-supervised learningWei Ye, Zexi Huang, Yunqi Hong, and Ambuj SingharXiv preprint arXiv:2201.09698, 2022
Graph Convolutional Networks (GCN) is a pioneering model for graph-based semi-supervised learning. However, GCN does not perform well on sparsely-labeled graphs. Its two-layer version cannot effectively propagate the label information to the whole graph structure (i.e., the under-smoothing problem) while its deep version over-smoothens and is hard to train (i.e., the over-smoothing problem). To solve these two issues, we propose a new graph neural network called GND-Nets (for Graph Neural Diffusion Networks) that exploits the local and global neighborhood information of a vertex in a single layer. Exploiting the shallow network mitigates the over-smoothing problem while exploiting the local and global neighborhood information mitigates the under-smoothing problem. The utilization of the local and global neighborhood information of a vertex is achieved by a new graph diffusion method called neural diffusions, which integrate neural networks into the conventional linear and nonlinear graph diffusions. The adoption of neural networks makes neural diffusions adaptable to different datasets. Extensive experiments on various sparsely-labeled graphs verify the effectiveness and efficiency of GND-Nets compared to state-of-the-art approaches.