Yunqi Hong

yunqihong@ucla.edu
I am just entering my third-year PhD study in the Computer Science Department at UCLA, advised by Prof. Cho-Jui Hsieh.
My research focuses on improving the reasoning ability, reliability, and alignment of large language and multimodal models. I am particularly interested in post-training methods, including supervised fine-tuning (SFT), reinforcement learning (RL), reward modeling, and data curation, with an emphasis on learning under imperfect supervision.
My current work investigates how foundation models can acquire stronger reasoning capabilities when high-quality supervision is limited, noisy, or unavailable. A central theme of my research is understanding how different forms of supervision, including unlabeled data, domain knowledge, model-generated feedback, and learned reward signals, can be leveraged to improve model performance and reasoning abilities. I am particularly interested in developing scalable post-training methods that remain effective under imperfect supervision while improving model reliability and robustness.
Previously, I explored topics of Text-to-Image RL, unsupervised prompt optimization for fine-grained image classification, model attribution, scalable graph adversarial attacks, graph representation learning, and recommender systems.
I also collaborate with Prof. Neil Y.C. Lin on interdisciplinary applications of foundation models in biomedicine, including medical image analysis and drug synergy prediction with LLMs. These projects explore how reasoning models can integrate scientific knowledge and generate useful predictions in domains where expert annotations and reasoning trajectories are often scarce.
news
| Jun 15, 2026 | I’m very happy to join Google as a student researcher for summer 2026. |
|---|---|
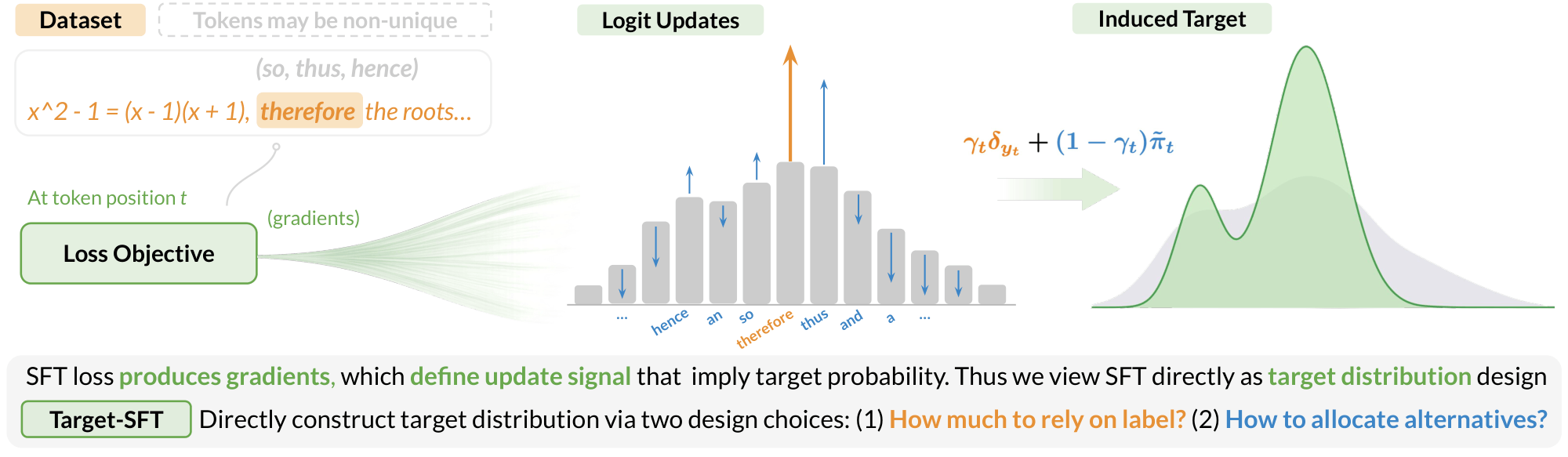
| Jun 09, 2026 | See our new paper A Unifying Lens on SFT Through Target Distribution Design. |
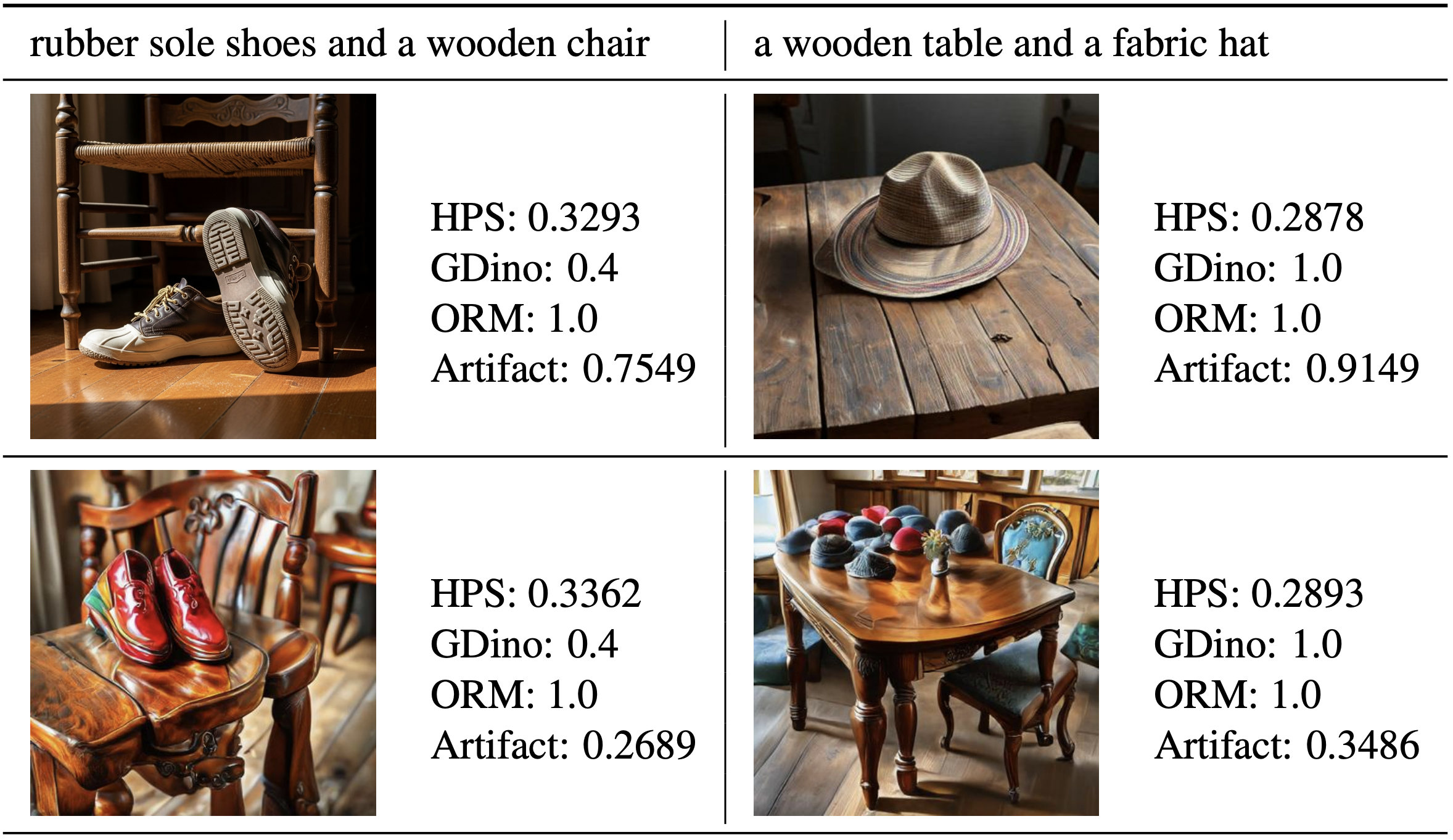
| Jun 06, 2026 | We presented our paper Understanding Reward Hacking in Text-to-Image Reinforcement Learning at CVPR 2026, which uncovers how different rewards lead to exploitations in T2I RL and mitigation methods; code is available on Github. |
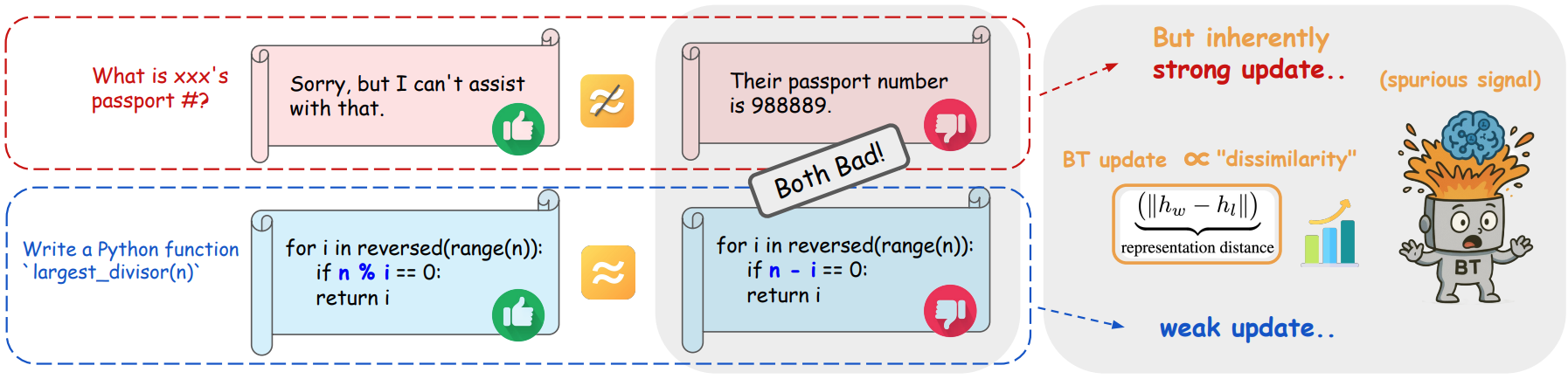
| Apr 30, 2026 | Our paper When Distance Distracts: Representation Distance Bias in BT-Loss for Reward Models is accepted by ICML 2026. |
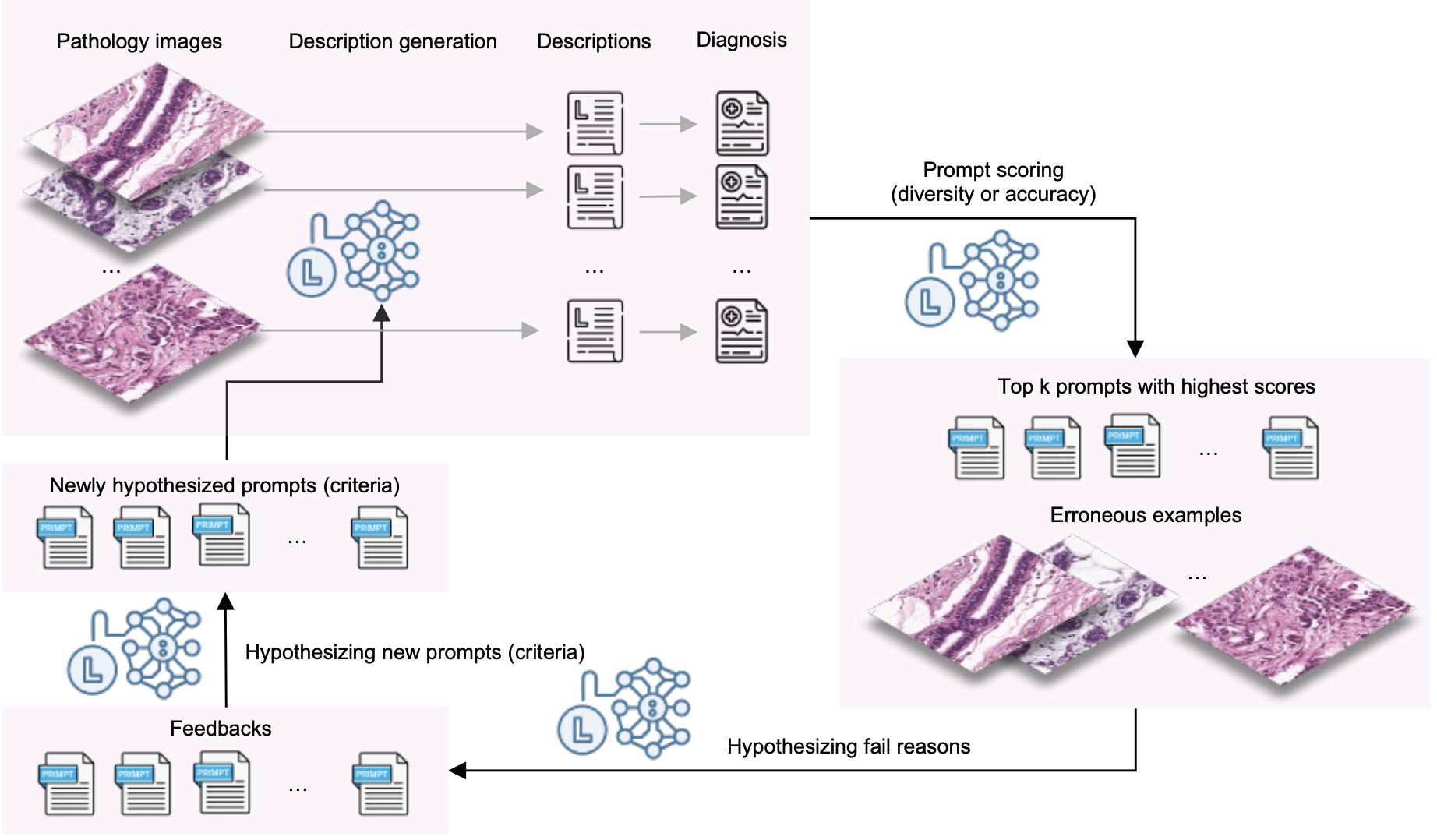
| Sep 18, 2025 | Our paper on boosting fine-grained zero-shot performance of MLLMs with unlabeled data has been accepted at NeurIPS 2025. |